





Making sure you monitor model performance after the production deployment of your machine learning model is crucial for maintaining its accuracy, reliability, and effectiveness in real-world applications. A lot can go wrong, especially if you have no process or approach for tracking model performance over time.
Monitoring should be a continuous process, leveraging tools and platforms that can automate many of these tasks to ensure real-time or near-real-time performance tracking. Adapting to changes by retraining the model with new data, tweaking features, or even redesigning the model architecture may be necessary to maintain optimal performance.

What factors should you consider to monitor model performance?
To ensure your model performs optimally, keep in mind the following considerations:
- Accuracy and Performance Metrics: during the training phase you should have established a baseline for key performance indicators like accuracy, precision, recall, or mean squared error. This baseline is vital to ensure the model remains effective post deployment for its intended purpose. Significant changes in these metrics relative to your initial baseline can signal the need for model updates or retraining.
- Data and Concept Drift: Monitor changes in input data distribution (data drift) and shifts in the relationship between input data and output predictions (concept drift). These drifts can degrade model performance over time, indicating the necessity for model adaptation or retraining.
- Resource Utilization and Latency: Keep an eye on the computational resources required for model operation, including processing time and memory usage. Increased resource demand or latency may point to inefficiencies that need optimization.
- Fairness, Bias, and Regulatory Compliance: Continuously evaluate the model for fairness across different groups to avoid biased outcomes, and ensure it complies with legal and ethical standards. Adjustments may be needed to correct biases and meet regulatory requirements.
- Feedback Loops and User Feedback: Be vigilant about feedback loops where the model’s predictions influence future input data, potentially leading to biased or inaccurate outcomes. Additionally, incorporate user feedback to identify practical issues or areas for improvement not captured by quantitative metrics alone.
Data and Concept Drift
Of the five factors above, one of the trickiest ones to monitor is data and concept drift. The efficacy of these models is not set in stone; they require ongoing attention and adaptation. Over time, the data you feed your model and the underlying relationships it captures can change, leading to what’s known as Drift—a phenomenon that can degrade a model’s performance if not properly managed.
Model Drift is categorized into two types: Data Drift and Concept Drift. Data Drift refers to changes in the input data’s distribution, which can naturally occur as data is updated or added. This drift does not always harm model performance, especially if new data remains within the model’s trained decision boundaries. However, when new data falls outside these boundaries, the model’s accuracy can deteriorate.
Concept Drift, on the other hand, involves changes in the relationship between input variables and the model’s output. An example would be the introduction of a new product category by a company, which could alter the propensity scores for certain accounts. This type of drift typically has a detrimental effect on model performance, as the model continues to operate on outdated assumptions until it is retrained to accommodate the new data landscape.
How to monitor model performance: propensity models
Propensity models are best monitored using confidence-based performance estimation (CBPE). The idea behind CBPE is that the ground truth for classification models is not always available post-deployment, and when it is it may be delayed. You generally want to know if your model is drifting right away, not months from now.
It turns out we can estimate the live performance of the production model by looking at both binary predictions and the associated probability (score). Using both gives us a sense of the confidence in the answer, meaning we can reliably estimate the current confusion matrix of the production model and therefore its current F1 score. Implementing model monitoring in Python can be complex and tedious, which is why it’s available out of the box in a no code platform like Analyzr. For each published model, Analyzr will track and show production performance vs. training baseline:
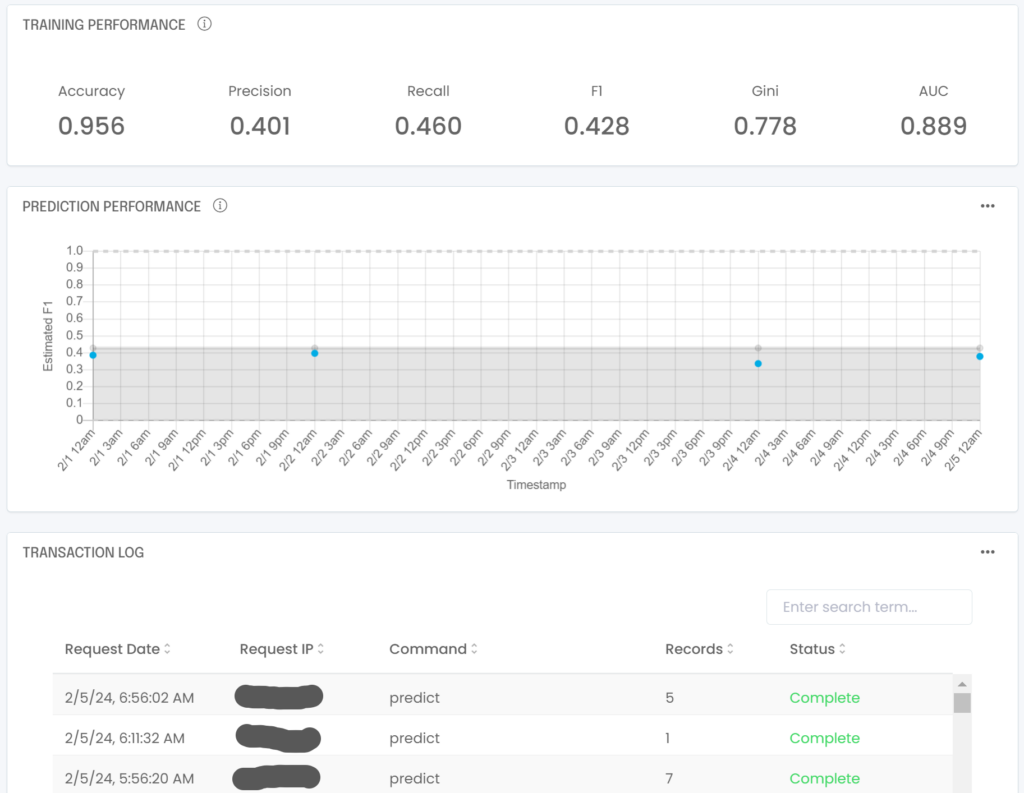
By comparing the model’s estimated F1 over time with its expected value computed during the training phase you can get a sense of whether your model is experiencing any data drift or not. The Analyzr model monitoring page will also provide upper and lower bounds for your model’s estimated F1 to indicate whether model performance is within its expected range or not.
Note that the CBPE approach will detect data drift and covariate shift but not concept drift. Concept drift is hard to detect methodically, so you should always be on the lookout for domain-specific changes which might invalidate your model, like know business or market transitions.
More details on the data science principles behind the CBPE approach can be found here.
How to monitor model performance: regression models
Regression models are best monitored using direct loss estimation (DLE). The idea behind DLE is that the ground truth for regression models is not always available post-deployment, and when it is it may be delayed. You generally want to know if your model is drifting right away, not months from now.
It turns out we can estimate the live performance of the production model by training a secondary model on the observed residuals associated with the primary model, i.e. using the difference between actual and predicted values generated by the primary model during its training phase. Using this secondary model we can then estimate the loss (specifically the root mean square error or RMSE) of the primary model post-deployment.
By comparing the model’s estimated RMSE over time with its expected value computed during the training phase you can get a sense of whether your model is experiencing any data drift or not. The Analyzr model monitoring page will also provide upper and lower bounds for your model’s estimated RMSE to indicate whether model performance is within its expected range or not.
Note that the DLE approach will detect data drift but not concept drift. Concept drift is hard to detect methodically, so you should always be on the lookout for domain-specific changes which might invalidate your model, like know business or market transitions.
More details on the data science principles behind the DLE approach can be found here.
How can we help?
Feel free to check us out and start your free trial at https://analyzr.ai or contact us below!
